This chapter
So far many different interprocess communication facilities have been
described. How fast are they? From the results of performance measurements
derived for this chapter conclusions can be drawn which communication
facilities to use in different situations.
A large number of programs were written for all described IPC
facilities which find out different aspects of their performance.
All performance measurements were done on three different systems to allow more general conclusions:
The performance of all IPC facilities is measured with different message/buffer
sizes (where appropriate) from 1 byte doubling up to the default limit of the
particular interprocess facility. This limit is sometimes different
on the three systems. Where limits are huge, an appropriate value is chosen.
The performance graphs are labeled double-logarithmic for two reasons:
This chapter summarizes the results derived from the various performance
measurement programs. The Appendix of the WWW-Version of this document
includes pointers to the generated raw results.
Interesting performance measurement outcomes are:
Number 1 is only interesting for interprocess-communication facilities
where a connection has to be established. Only the TCP connection example
has this property. Possible similar measurements
for filesystem dependent IPC facilities were not done for the following
reason: the speed of these is highly dependent on the file system (and not
of the operating system), and these are distributed for aidan and
all pikes. This would have had an unpredictable impact on the results.
Number 2 is interesting for all examples that are able to transfer larger
amounts of data. Most of the interprocess examples include this property.
The result is measured in Kb (1024 bytes) per second.
Number 3 is useful for nearly all examples. The resulting graphs show
how much non-avoidable overhead is involved with a certain operation.
The results are given in ![]() s per operation (where appropriate for a
specific buffer size). Some other results are also given in operations per
second.
s per operation (where appropriate for a
specific buffer size). Some other results are also given in operations per
second.
For all measurements passed clock time is used to display the results, as this
is the time the user/program becomes aware of. If CPU time is measured,
accumulated system and user CPU time is given.
To measure the time in the different interprocess communication facilities some functions and classes were coded. They measure the
Time measurements on computers normally have an impact upon the time they should measure. To ensure that the measurements do not influence the measured time too much, it is important to know how long the measurements take. The overhead for the two described classes clocktimer and cputimer is measured with the program performance/timeroverhead.c. This is the result of running the program on SparcCenter 2000/Solaris 2.5:
performance/timeroverhead.log.SunOS5
It can be seen that the overhead is not very high. Therefore the overhead
of measuring the time is ignored in all performance measurements.
To reduce the influence caused by the measurement and other temporary
differences all measurements are done several times
(normally 1000 or more times).
The measurements were done in such a way that the influence of other
interferences (other users using the computer systems at the same time etc.)
was kept to a minimum.
The precision of the internal timers of a computer system has an
influence on the accuracy of the measurements. The precision of the used
CPU time is normally much lower than the precision of the ``real time'' clock.
The precision of the used CPU time is 1/100 second on all used systems,
whereby the clock precision is reported to be accurate to some ![]() s.
s.
To reduce the replication of code for measuring time the class
measurement, defined in common/measurement.h, was developed.
It uses the classes cputimer and clocktimer internally to measure
time. The measured time is written to an internal memory buffer. This avoids
time consuming I/O operations which could influence the measurements.
The measured times can later be written out in various ways.
UNIX system calls introduce a non-avoidable overhead. This overhead was
measured with the program performance/systemcalloverhead.c. This
program measures the time of a getpid() system call. This system
call is
regarded as one of the cheapest system calls in a UNIX operating system,
as it has only to copy an integer value (the process number) from the
kernel to the user process. The result is shown in Table 20.
In all following measurement descriptions the number of system calls made to get the measured data is included. The non-avoidable overhead is not subtracted from the measured results, as programs/users experience these delays.
UNIX signals were used in some measurement programs to synchronize the measurement of different processes. The program performance/signaloverhead.c measures how long it takes to send a signal from one process to another and to get a response signal. The described operation involves two system calls: kill() and sigsuspend(). This is the result of the program performance/signaloverhead.c on SparcCenter 2000/Solaris 2.5.
performance/signaloverhead.log.SunOS5
Table 21 shows how often the described operation can be done on the different systems.
Signals are used in some of the local interprocess communication examples
to synchronize corresponding processes. Some functions defined in
common/synchronize.c hide the implementation details of
how to synchronize related processes via signals.
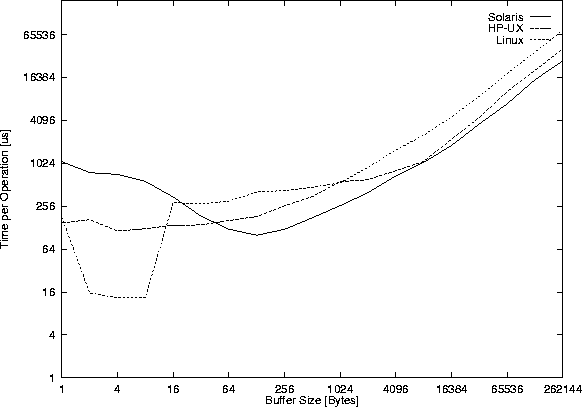
Program performance/pipes.c measures the performance
of pipes with different buffer
sizes for read() and write() operations.
Figure 32
shows the measured unsynchronized read() throughput,
while Figure 33 shows
the time for the (also unsynchronized) read() function calls.
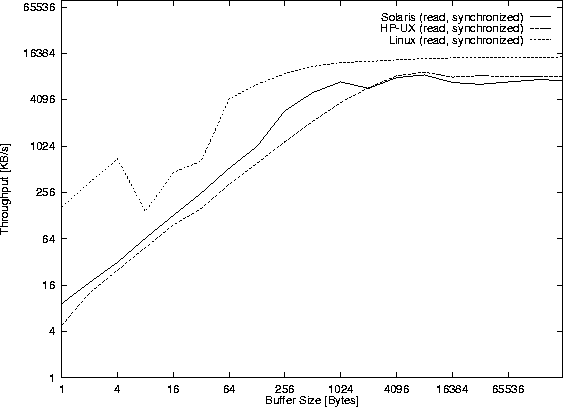
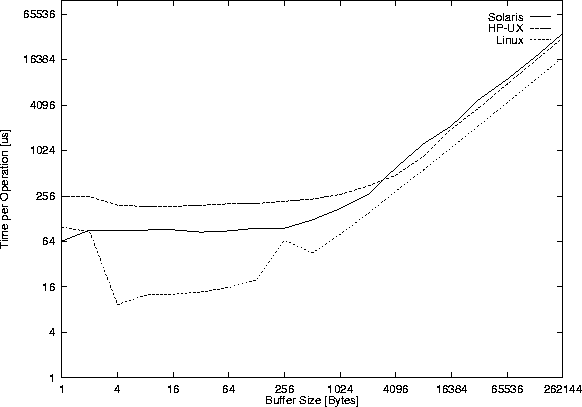
The write counterpart is not shown as the read() and write() results are nearly the same. It can not be said how much read()/write() operations are involved in getting the data due to the different read() semantic for pipes, FIFOs, sockets etc. The problem is that I/O operations can return less than the requested amount of data, and therefore the system call might have to be issued again and again till all data is read/written (common/readn.c and common/writen.c handle these cases). Details about this problem are given in [Stev92, page 406].
The performance of named pipes is measured with the client/server pair of
programs performance/fifoclient.c and
performance/fifoserver.c. Figures 34 and
35 show the results only for the read()
system calls, as the corresponding write() system calls are nearly
equal.
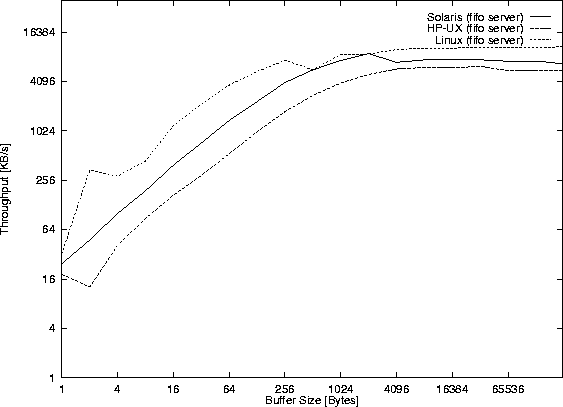
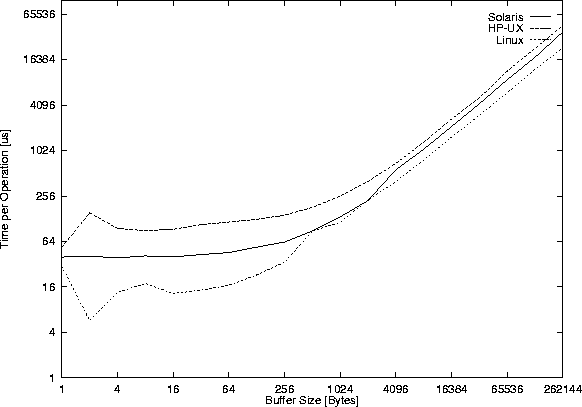
At least one read()/write() system call is issued for each buffer size.
The program performance/message.c was used to measure the performance
of message queues. Figure 36 shows their throughput, and
Figure 37 the time per msgsnd() system call.
Please note that the maximum size of messages is quite small, it was less than 4k on all three systems.
Semaphores are not used to transfer information, they are used to
synchronize access of different processes to other resources.
How many semaphore operations can be done per second? The rounded result
for one semop() system call derived with the program
performance/semaphore.c for
the different systems is shown in Table 22.
Please refer to Chapter 3.5.2 for the meaning of the undo facility of semaphores.
The program performance/memory.c is used to measure if there
is any time penalty in writing to shared memory instead of normal
memory. A buffer of 1 Mb in ``normal'' memory and an equally sized
shared memory region is allocated. The program writes zeros in both buffers.
A read test could not be performed, as the compilers optimized the read
code to ``nothing''.
The best results are given in Table 23.
The results suggest that there is no difference in accessing ``normal''
and shared memory. No system call was used to write into the memory.
One might ask how big the overhead is to establish memory sharing. Figure 38 shows the time needed to create, attach, detach and remove a shared memory region of different sizes. Four system calls were used per operation: shmget(), shmat(), shmdt(), and shmctl().
As already described in Chapters 3.4 and 6.1.5
the socketpair() system call can be used to create a
bi-directional pipe. The
program performance/socketlocal.c is nearly identical
to the corresponding program performance/pipes.c
using the pipe() system call.
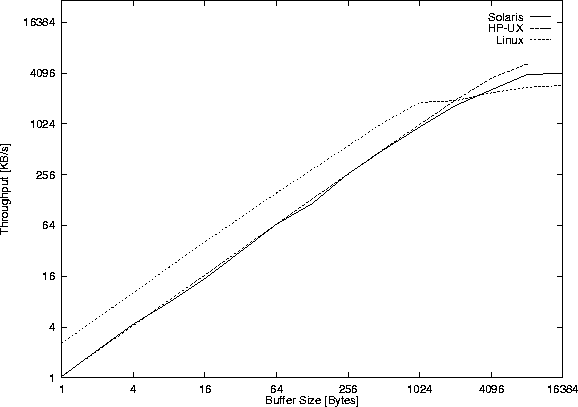
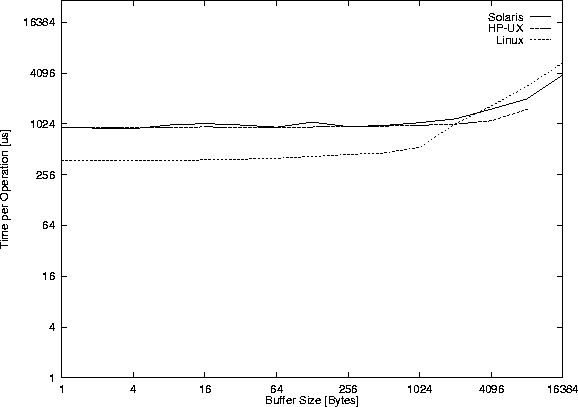
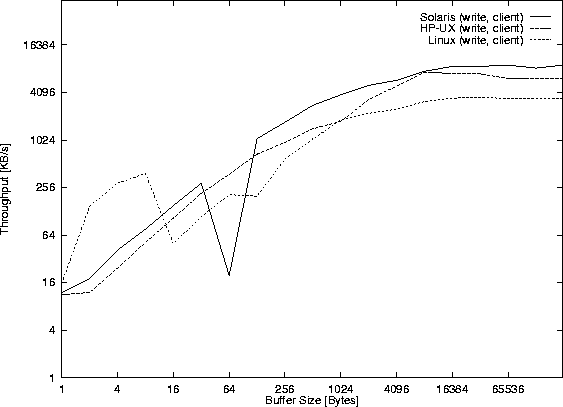
Figure 39 shows the throughput of local sockets,
Figure 40 the time for the read() system calls.
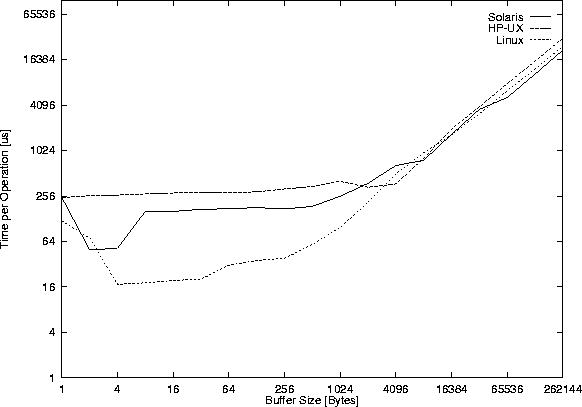
The performance (comparing Figure 39 with Figure 32 ) is roughly that of the pipe() version, and in fact most pipe() implementations today seem to be implemented by using the socketpair() system call.
The client program performance/udpsclient.c measures the time that
UDP messages need from one process to another. The sender waits for a short
acknowledgment message from the server performance/udpsserver.c.
Figure 41 shows the throughput if server and
client are running on the same system, and Figure 42
the throughput between aidan and pike17 and also the throughput
between two HP 9000/710 computers on the same physical Ethernet.
The time for the corresponding system calls can be seen in Figures
43 and 44. Per operation the
following system calls are executed both in the client and in
the server process: recvfrom() and sendto(). Please
note that the default maximum size for UDP was
different on the used systems,
it was 16 Kb on SparcCenter 2000/Solaris 2.5 and i586/Linux 1.2.9, and less than 16 Kb on HP 9000/710/HP-UX 9.01.
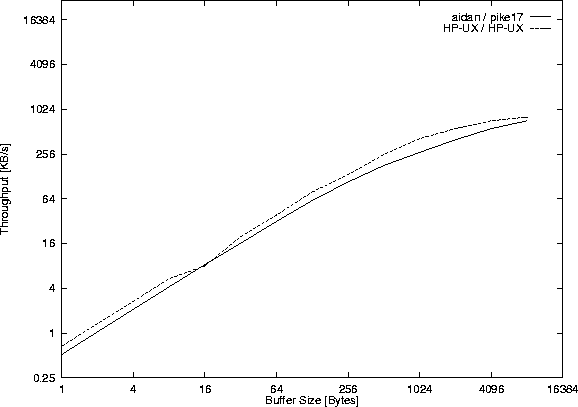
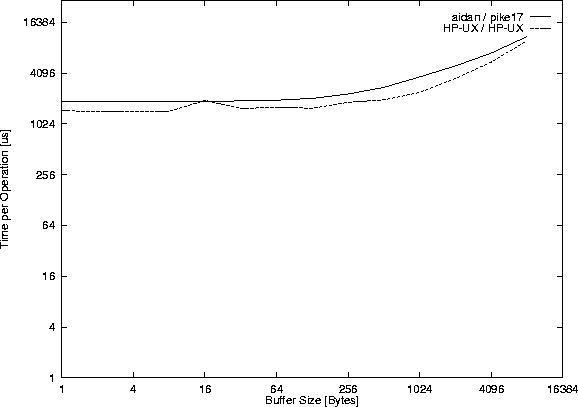
The computers aidan and pike17 are not connected to the same
physical Ethernet, which explains why the throughput is slower between
them compared to the two pikes.
UDP is not reliable. This had an impact on the measurement between different computers. The number of repeats for each buffer size had to be reduced, as none of the tests otherwise succeeded (the measurement program relies on data to be delivered, as in the case of a not delivered message both client and server are waiting for each other forever).
The client program performance/tcpsclientoverhead.c together with the
server program performance/tcpsserverconcurrentoverhead.c is
used to measure the overhead of establishing a TCP connection.
The connection establishment measurements include the execution of
the system calls socket(), connect(), and close()
on the client side and
accept(), fork() (the TCP server is implemented as a
concurrent server which can handle multiple requests simultaneously), and two
close()s on the server side.
The rounded results are given in Table 24.
For comparison: on average it takes about 6600 ![]() s to establish a connection
from aidan to pike17, and 2400
s to establish a connection
from aidan to pike17, and 2400 ![]() s between two pikes on
the same physical Ethernet.
s between two pikes on
the same physical Ethernet.
Figure 45 states the throughput of a local TCP
connection. The executed system calls are (eventually several) write()s
on the client side and (eventually several) read()s on the server side.
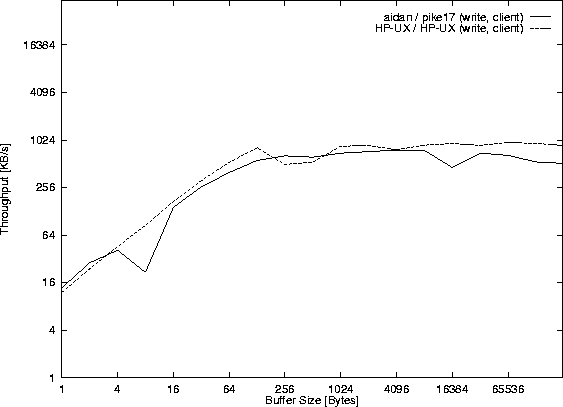
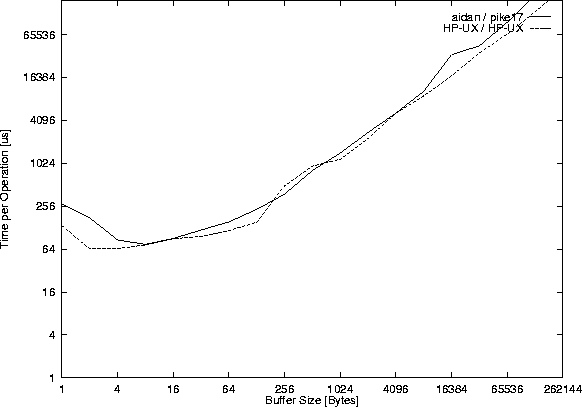
The client program performance/tcpsclientthroughput.c together with the server program performance/tcpsserverconcurrent.c, which measured the data for Figure 45, were also used to measure the TCP throughput between two HP-9000/710 computers on the same physical network and the TCP throughput between aidan and pike17. The result is shown in Figure 46. The used time for the corresponding read() system calls is shown in Figures 47 and 48.
The UDP and TCP measurements were also performed using the TLI interface on
aidan only, as the other systems unfortunately do not support the
Transport Layer Interface.
The results were similar to the ones from the socket interface (about 20% slower for TCP throughput and about 15% slower for UDP throughput), therefore the results are not shown here.
The IPC facilities which were investigated have major differences in
performance.
The three different systems produce dramatically different performances,
but in principle their behaviour for a specific
IPC facility is very similar.
To synchronize processes on one computer systems semaphores should
be used instead of signals, as the overhead of signals is dramatic,
caused by the context switch that has to be done.
The size of the buffer has a great impact on the throughput of a local
IPC facility. Up to about 4 - 8 Kb (dependent of the system and the
IPC facility) larger buffers normally produce a larger throughput.
This is likely to be caused by the overheads of the system calls.
Larger buffer sizes do not cause major performance loss or
gain.
For interprocess communication on one computer, shared memory is the
fastest way to transfer huge amounts of information from one process to
another. There is no penalty in using shared memory instead of normal
memory. The size of the shared memory region has nearly no impact on
the time that is needed to create, attach, detach, and remove a shared
memory region.
Message queues, originally designed to provide a faster form
of IPC are now slower than other forms of IPC (possibly caused by the
small buffer sizes). They therefore should not be used for high speed
information exchange any more. The possibility of selecting messages
by priority may justify their use for some purposes.
For distributed IPC facilities the time to transfer the data has a stronger
influence than on the local ones. Therefore the time of an operation is
more proportional to the amount of data transfered than in the local
IPC facilities.
UDP is faster than TCP at transferring data between different computers,
but the application has to take care of lost packages, congestion,
flow control etc. On aidan and on the pikes the local use
of TCP has a much higher throughput than UDP.
The overheads of establishing a TCP connection are quite high. If only small
amounts of data have to be transfered, UDP should be used. In the time
needed for a connection establishment, UDP might already have transfered all
the data.
The speed of TCP used locally on a system is not dramatically slower
than equivalent local IPC facilities (e.g. pipes), at least on aidan
and the pikes. Therefore where speed is not very critical,
applications that might be distributed, should use TCP wherever possible
instead of pipes and local sockets.
Most IPC facilities have a fixed time overhead per operation. Up to a
specific buffer size the time per operation is nearly independent of the
buffer size used.
Tables 25 and 26 present the most appropriate facility which should be used for particular purposes. ``UDP'' and ``TCP'' should be read as using sockets or the TLI with the specified protocol.
| Connection Type | Local | Distributed |
| Connection-oriented, reliable | pipes, FIFOs, stream sockets, (shared memory) | TCP |
| Connection-oriented, unreliable | - | - |
| Connectionless, reliable | message queues, semaphores, signals | - |
| Connectionless, unreliable | datagram sockets | UDP |
Various measurements were done on three different systems to get
information about the performance of different interprocess communication
facilities.
The performance difference between the three systems is sometimes high,
but the characteristics are very similar. Shared memory is the
fastest mechanism to transfer large amounts of data between processes on one computer,
while UDP is the IPC mechanism with the highest throughput between different
computers. The size of buffers should not be less than 4 Kb if larger
amounts of data are exchanged.
The performance measurements demonstrated the unreliability of the UDP protocol. Therefore the next chapter examines what is necessary to ensure reliable datagram exchange.