This chapter
UNIX programming and networking is a very wide field. Therefore before
it was decided what to cover in this document a lot of books
and articles were read. It turned out that only certain aspects of the
UNIX communication facilities could be covered due to the limited amount
of time and space.
This individual project therefore concentrates on analysing the traditional
UNIX system
programming level. Higher level applications and protocols are only
mentioned (if at all), but not covered in detail.
The different versions of UNIX complicated the programming. The availability
of certain UNIX features differed quite a lot. To understand the differences
and future directions of the UNIX operating system, an overview about existing
and future standards, together with an overview of UNIX history are
given later in this chapter.
The description of local IPC features was the easiest part. As networking
adds a lot of complexity it was decided to cover the principles of networking.
Without this knowledge it is not possible to understand how
``distributed'' IPC facilities fit into the overall picture.
With the OSI protocol implementations declining in popularity
([Salus95]) it was decided to investigate only
the TCP/IP protocol suite. This suite offers a working
solution for today's most important networking demands. TCP/IP is used
in the Internet, and, particularly, in the UNIX environment it is the
standard.
The performance measurements were done on three different computer systems.
This was done to be able to make more general assumptions about the
performance of certain IPC facilities.
Some techniques and feature developments deserve to be mentioned in a document
that has the title ``UNIX Communication Facilities''. Therefore IPng
and OSF DCE are summarized in the conclusion chapter.
The chosen programming language for all example programs was
C/C++. UNIX has a strong connection to C: UNIX is written in C, to be precise,
C was developed to fill the needs for a powerful low-level general purpose
language for making the UNIX operating system portable. C is therefore
the `natural' language to program UNIX systems.
Today C++ is the industry choice to write large software systems. C++ is
a hybrid language, it combines object-orientation and declarative programming
so that C code is still valid C++ code. All examples therefore use the benefits
of C++, but use the C interface to make UNIX system calls. No attempt was made
to hide the use of the UNIX system call interface, as it was one goal of the
individual Project to explore it. In the real world certain software classes
would be used to hide some of the operating system details from the
programmer. Two of them are mentioned in
Chapter 9.4.2.
This document only addresses certain aspects of ``UNIX Communication Facilities''. Some subjects had to be omitted due to space or time (or both), although they are important and interesting areas. These are some limitations of the project:
The UNIX interprocess facilities can only be understood with the historical
background.
UNIX was originally developed by Ken Thomson (and
later Dennis Ritchie) at Bell Labs (AT&T) to get a ``leaner''
MULTIX operating system. Originally UNIX was written in assembly
language on a PDP-7 minicomputer.
Later (1973) UNIX was rewritten in C, which was developed to make UNIX
highly portable.
Design principles were that it should be as simple and elegant as possible
(no different file types etc.).
Therefore only pipes were used/developed as interprocess
communication facilities.
UNIX was first used for word processing in AT&T Bell Laboratories.
Bell Labs were asked for a copy of UNIX from many Universities.
As AT&T was a regulated monopoly at this time, it was not permitted
to be in the computer business, and therefore Bell Labs gave the source code
away for only a small fee.
The University of California in Berkeley became a major center of
UNIX development. The Computer Systems Research Group (CSRG)
at the University of
California in Berkeley was partly sponsored by DARPA, the Defense Advanced
Research Projects Agency. Berkeley's first release of an enhanced UNIX was 1BSD
(First Berkeley Software Distribution). 3BSD added virtual memory, while 4.2BSD added interprocess communication
facilities (sockets) that made networking possible.
BSD used TCP/IP as network protocol, which became a de facto standard.
The 4.4BSD release (1993) was the last release from CSRG
for reasons stated in [Bost93].
AT&T was split up in several companies in 1984. The new AT&T was allowed
to enter the computer market, and it did. Shortly thereafter, AT&T released
its commercial version of UNIX, System III, which was replaced by System V
a year later. The original System V was further developed into releases 2,
3, and 4, which got more and more powerful, complicated and bigger.
System V added message queues, semaphores, and shared memory to the
interprocess communication facilities.
AT&T recently sold UNIX System Laboratories (USL), the subsidiary which
developed the AT&T version of UNIX, together with all
interests in UNIX to Novell.
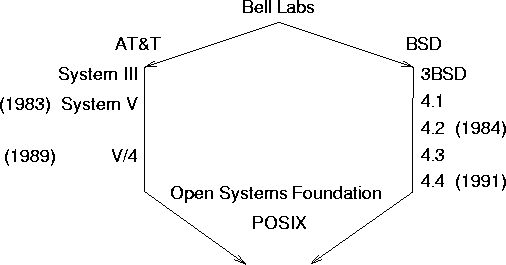
Most UNIX systems are based either on the AT&T version of UNIX (e.g. HP-UX
from Hewlett-Packard, AIX from IBM), or Berkeley UNIX (e.g. Solaris
(former SunOS) from SUN or Ultrix from DEC).
Both derivatives have added the more important features of the other
UNIX direction. Figure 1 shows the development of the two major UNIX
directions.
As a result of the above there were two different and quite incompatible versions of UNIX around in the late 1980s. Some companies added additional features to their
version of UNIX. This produced a need for standards. All initial attempts
failed. AT&T issued the System V Interface Definition (SVID) (various
versions for different UNIX versions, e.g. SVID Issue 3 in 1989 for System V
Release 4 (SVR4)) as a
standard to keep all the System V vendors ``in line'', but this standard
had no effect on
vendors which based their version of UNIX on BSD's UNIX.
This split of UNIX is still noticeable and makes it complicated to write
UNIX programs which should be portable between these two UNIX directions.
A more serious attempt to reconcile the two UNIX directions was initiated by
the ``neutral'' IEEE Standard Board. The POSIX project with its standards is
highly accepted in the industry. A well known standard is 1003.1 (sometimes
also called POSIX.1), which is only one part of the POSIX standards (see
Table 1).
| Standard | Description |
| 1003.0 | Guide and overview |
| 1003.1 | Library Functions (i.e., system calls) |
| 1003.2 | Shell and utilities |
| 1003.3 | Test methods and conformance |
| 1003.4 | Real time extensions |
| 1003.5 | Ada language bindings |
| 1003.6 | Security extensions |
| 1003.7 | System administration |
| 1003.8 | Transparent file access |
| 1003.9 | Fortran 77 bindings |
| 1003.10 | Supercomputing |
POSIX is still working on standardizing UNIX, but its work has also influenced
other operating systems. Most modern operating systems try to be POSIX
compliant.
Another big problem was a split of vendors. A group of vendors including
IBM, DEC, and Hewlett-Packard did not like the idea that AT&T had control
over the ``official'' UNIX. They set up Open Software Foundation (OSF), which has the aim
to produce a system that conforms to all IEEE standards, but also contains
a large number of enhancements like a window system (X11), a standardized
graphical user interface (MOTIF). OSF also develops DCE (Distributed
Computing Environment), which ``provides services and tools that support
the creation, use, and maintenance of distributed applications in a
heterogeneous computing environment'' [OSF DCE, page 1].
The reaction of AT&T was to set up UNIX International (UI) as a
vendor-independent controlling body for the future of UNIX, which had similar
aims. For years there has been a fight between UI and OSF.
As stated above AT&T sold UNIX to Novell recently.
With the threat of Windows NT from Microsoft
the time for fights between OSF and UI is over; today UI has no significant
industry relevance any more.
X/Open (a consortium of industry representatives with a common charter for developing open system specifications) has three goals:
X/Open concentrates on the needs of end users. This makes X/Open more vendor
neutral than most other organizations.
The Object Management Group (OMG) has developed a set of standards for the
use of objects. The most known is the Common Object Request Broker
Architecture (COBRA).
Another standard influenced UNIX: the standardization of C, known as ANSI C.
A detailed description of different flavours of the UNIX Operating System can be found in [Pab93, page 3-13]. A more detailed description of the UNIX history can be found in [Tan92]. A more detailed description of standards and industry organizations can be found in [Tan92] and [Elb94]. Some networking standards are mentioned in Chapter 4.7.
Chapters 3 (Local IPC) and 6 (Distributed IPC)
contain example programs for each IPC facility. The programs were designed
to be reasonably short so that they can be understood without referring to
other functions. Due to space limitations the source code itself is not
included or described in the chapters which give the overview of the
different IPC facilities. Nevertheless the examples are an important part of
understanding a particular IPC facility and therefore this
Individual Project.
The principles of communication and the client/server model
are important
for understanding interprocess communication facilities. Therefore
they are described in detail later in this chapter.
Most examples in this document use the client/server concept.
The programs which measure the performance of the different IPC facilities
in Chapter 7 are normally very similar to the ones
used as an example. This aids understanding of the performance
measurement programs.
All programs try to conform to the POSIX.1 standard as far as possible.
This is, unfortunately, not easy and sometimes even impossible. This is due
to the fact that networking and some forms of local IPC are not covered by
POSIX standards (yet) and the systems available may not offer specific
features.
All developed functions, classes, and programs were intensively tested. Developed functions and classes were first tested individually, before they were used by more complex programs where possible. Debug code that prints internal states of interesting variables, while the program was being executed, was also used. Both the test functions and the debug code were removed to keep the program source shorter and to make them easier to read. These test programs are also not included in the appendix due to limited space. The test code for one function is preserved to demonstrate how test code looked like (see local/namedstreampipe.c).
The principle methods of communication between different endpoints of communication are
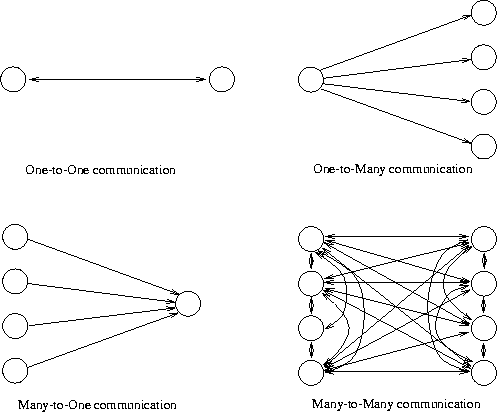
Only the first form of communication is described in this document.
The second one is normally only supported by local network types like Ethernet
and therefore not discussed further. If methods 2 to 4 are needed
they normally have to be implemented in software using point-to-point
communication. Some problems in implementing these methods are to ensure
that the
communication is reliable (all endpoints get the information or none of them),
and that the data is delivered to all receivers
in identical order. These problems are beyond the scope of this document.
One-to-one communication can be classified further by the type of connection.
Communication is termed connection-oriented if both communication
endpoints establish a (logical, virtual) connection before the actual
data exchange can take place. A connection-oriented exchange involves three
basic steps: connection establishment; data transfer; and connection
termination. An example for connection-oriented communication is the
use of telephones, where one has to dial before it is possible to
speak with the person on the other end.
Connectionless communication uses messages (often called datagrams)
to transmit information. These datagrams are transmitted independently.
Therefore each datagram has to contain all information to reach the
destination. Datagrams normally have a fixed length, can arrive in a
different order than they were sent, and can get lost. Communicating
with someone else using letters is a good example for connectionless
communication.
Table 2 [Tan88] summarizes the major
differences between connection-oriented and connectionless services.
| Issue | Connection-oriented | Connectionless |
| Initial Setup | Required | Not possible |
| Destination address | only needed during setup | Needed on every packet |
| Packet sequencing | Guaranteed | Not guaranteed |
| Error Control | Done by network layer | Done by transport layer |
| Flow Control | Provided by network layer | Not provided by network layer |
| Are connection identifiers used? | Yes | No |
Connection-oriented communication can be classified further by how
information can ``flow''.
With the simplex communication method data
can only flow from one
endpoint to another endpoint in one direction.
If the direction of data can be changed, but only one endpoint can
send data at a time, communication is called half duplex.
Full duplex or bi-directional communication allows flow of data
in both directions at the same time.
Communication can be blocking or nonblocking. A send or receive
operation is called blocking if the operation does not return till
the operation is completed. Nonblocking operations return immediately.
Comprehension of the client/server model is very important to help
understand UNIX communication
facilities. Therefore the idea of the client/server model,
and how this model is normally used in UNIX, is now covered.
In the client/server model two or more processes, eventually running on
different computers, work together to provide a specific service.
The communication scheme is normally like this: one process (called
the client) sends a request (it requests a service)
to other processes (called servers).
These servers send a reply back to the client.
These interactions are illustrated by Figure 3.
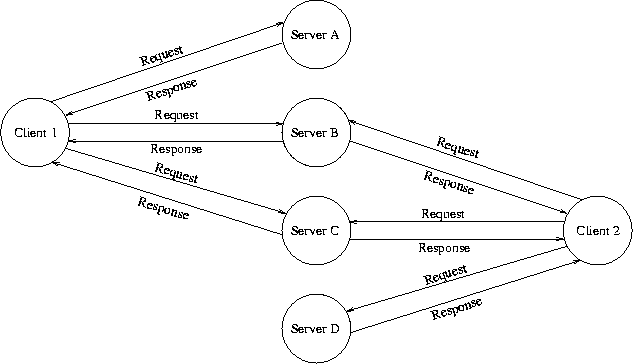
Two different kinds of servers are distinguished: so-called
concurrent servers that can handle multiple requests at the same
time, and so-called iterative servers which handle one request
after the other. A typical example of an iterative server is a server
that replies with the time on the computer where the server is running.
Concurrent servers are normally used if an answer can not be sent back
immediately, or if there is additional communication with the client.
Often concurrent servers use connection-oriented protocols.
Concurrent servers in UNIX often spawn other processes via
fork() to handle a request. Example: most servers that deal with the
transfer of files are implemented in the concurrent fashion, as the
amount of processing required depends on the file size.
Iterative servers are ideal if requests can be handled very quickly and the
replies are short. Normally connectionless protocols are used for iterative
servers.
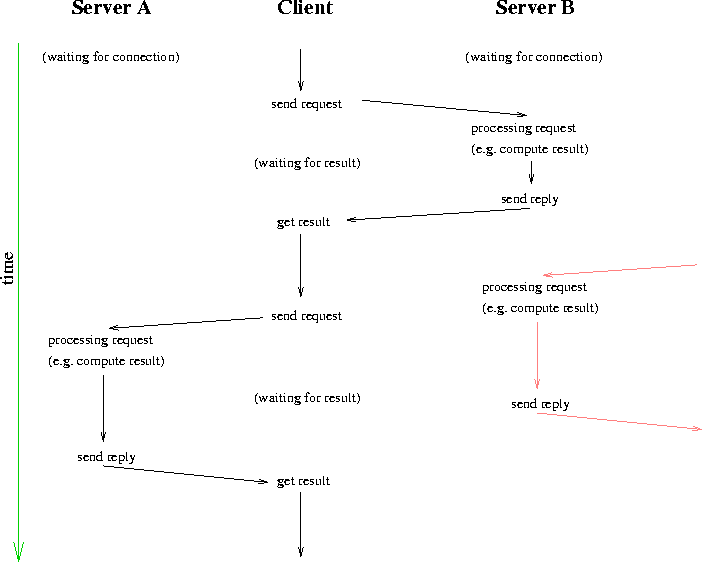
A client in the UNIX environment is normally the part of an application
that is run by a user. The servers are normally daemons (servers
are normally called this in the UNIX world) that are either
started automatically on system boot, or when a request for this
service arrives (by the inetd daemon). Once started, daemons normally
stay in memory till the computer is rebooted (they do not die).
Note that most daemons spend most of their time waiting for a request
to handle.
It is possible that the client and server both run on one computer, but
this is not necessary if they use network communication facilities to
communicate.
Other definitions of client/server computing can be found in
[Stall95, page 510]
Most examples in this project try to implement the client/server model, using different communication facilities.
Interprocess communication allows different processes to communicate
via a small and comprehensive set of interaction possibilities between
process. If interprocess communication mechanisms are used exclusively
for the interaction between different processes, they force a clean
and simple interface between them [Mull93].
Interprocess communication mechanisms serve four important functions [Mull93]:
The main aim of interprocess communication facilities is to deliver information with minimum latency and maximum throughput. For the delivering of continuous media like video it is also important to keep the irregularity of the latency to a minimum. If communication takes place over networks, interprocess communication facilities should hide as many failures as possible.
Some terms are defined to avoid confusion in the following chapters.
A program is an executable file. It is usually created by
a compiler, assembler and a linker.
A process is a program that is being executed by the computer's
operating system. If it is said that two computers communicate
it is meant that two processes on these computers communicate (after
[Stev90]).
UNIX processes normally use descriptors to reference I/O streams.
A descriptor is a small unsigned number that refers to a particular stream.
Read or write system calls can be applied to a descriptor to transfer data.
The close() system call can be used to deallocate any descriptor
(after [Leff88]).
The core UNIX operating system running on a computer is
called kernel. The kernel provides basic services like
memory management, CPU scheduling, file systems, and device I/O.
A computer network is a communication system for connecting
end-systems (computers which run applications on behalf of users).
End-systems are often referred as hosts if they are connected
to a network. Where a large number of hosts are to be connected, so that
any host may exchange data with any other, intermediate computers are
usually used, which are referred to as network nodes.
Occasional references are made to the UNIX manual pages for additional
details on a certain feature. The 8-section format used by both BSD
and System V is assumed. References of the form foo(2) refer to
the entry for foo in Section 2 of the UNIX manual (after [Stev90]).
The design and analysis for this document are sketched.
Some helpful background information is given.
Historically interprocess communication was a weak area of UNIX, but now
a wide range of options is available. The two most important
UNIX directions
are System V from UNIX System Laboratories and BSD by the Computer Systems Research Group at the University of California at Berkeley. A lot of UNIX
standards have been developed.
Principles and aims of interprocess communication were stated. Some important
terms are explained.
The client/server model is important in the UNIX world. Most example programs
in the following chapters try to use this model.