This chapter covers
TCP/IP is the protocol suite for UNIX interprocessor communication. Therefore some knowledge about it is needed. This chapter gives an overview of some aspects of the TCP/IP protocol suite. Chapter 6 describes how this protocol suite can be used from applications for interprocess communication.
The TCP/IP or Internet Protocol suite consists of several protocols. The more common ones are:
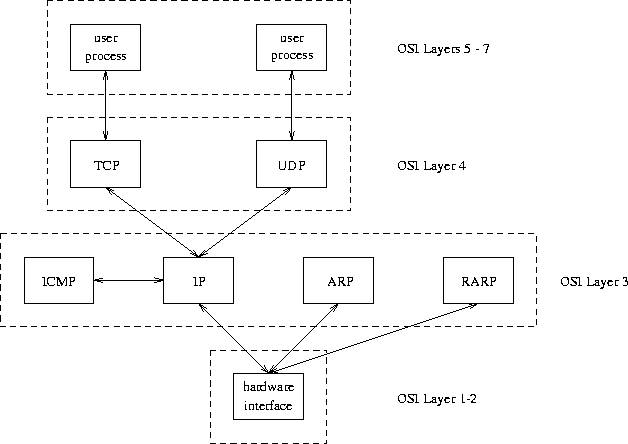
Figure 17 illustrates the relationship of these protocols.
The following text concentrates mainly on UDP and TCP, as
these are directly accessible from user processes.
The network byte order in the TCP/IP protocol suite is the big endian byte
order. This byte order is required for all integer values which are not
part of the transmitted data.
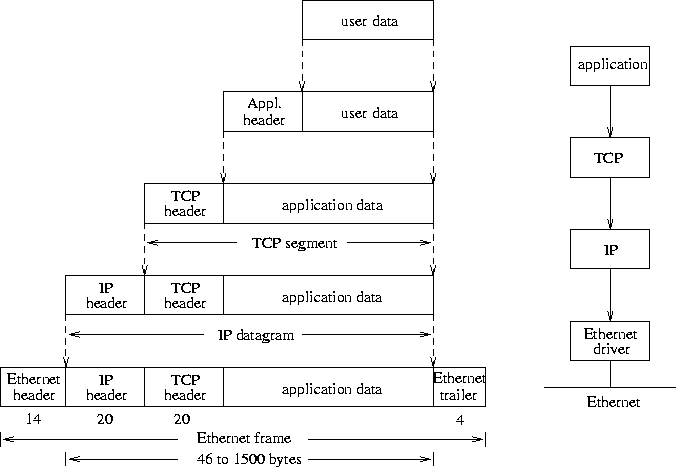
As with all layered protocol suites, every protocol layer encapsulates
the data from the previous level. This is shown in Figure 18
for data flowing down the protocol stack to the Ethernet level.
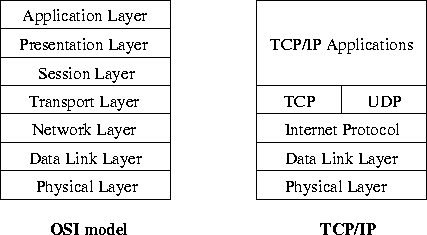
The TCP/IP protocol suite can be compared with the OSI reference model quite easily. Typical TCP/IP applications like ftp, telnet or SMTP cover layers 5 to 7. UDP and TCP are comparable to the transport layer, layer 4. IP and some other protocols cover layer 3, the network layer. Layers 1 and 2 (data link and physical layer) are not defined by the TCP/IP protocol suite. Here Ethernet or other suitable protocols are used. Figures 17 and 19 illustrate the relationship.
The Internet protocol suite, TCP/IP, was developed by the Defense Advanced
Research Projects Agency (DARPA) in the mid 1970s, with the architecture and
protocols taking their current form around 1977-79.
The technique selected for multiplexing was packet switching, as
the applications which should be supported were naturally served
by the packet switching paradigm, and the networks which were
to be integrated together were packet switched networks.
The top level goal for the DARPA Internet Architecture was to
``develop an effective technique for multiplexed utilization of
interconnected networks'' [Clark88]. This goal was reached,
and now thousands of networks (connected or not connected to the famous
Internet) use the TCP/IP protocol suite.
Second level goals were (in decreasing order of importance):
communication must continue despite loss of service;
support for multiple types of service; the Internet architecture
must accommodate a variety of networks; permit distributed
management of resources; be cost effective; permit host attachment
with a low-level of effort; and resources used must be accountable.
Especially one goal, the continuing of communication despite loss of service,
had a major impact on the design. To achieve this goal, the state
information which describes the on-going conversation
must be protected. Therefore this information is gathered at the
endpoints of communication, no intermediate packet switching nodes
need to have any state information.
A detailed review of the design philosophy of the DARPA Internet protocols is given in [Clark88].
Each host on a TCP/IP internet is assigned a unique 32-bit internet or
IP address
that is used in all communication with that host [Com95].
This address encodes the identification of the network to which a host
is attached to (netid) as well as the identification of a host on
that network (hostid). Therefore IP addresses do not specify
an individual computer, but rather a connection to a network.
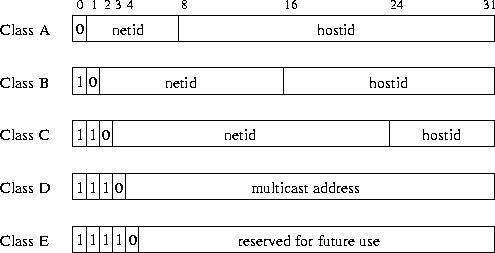
Five different sized classes A to F of IP addresses exist (see
Figure 20). Classes A to C are used
to identify hosts.
IP addresses are normally written as four decimal integers separated by
decimal points (dotted decimal notation), where each integer
corresponds to 8 bit of the 32 bit address. An IP address (binary)
Table 12 shows the ranges of IP addresses for the different classes.
Addresses not shown are reserved for special purposes, e.g. 127.0.0.1 is
a loop-back address for the local host. This feature was used to
measure the performance of distributed IPC facilities between processes
on the same computer for Chapter 7.
For humans numbers are still difficult to remember. Therefore each host can
have a symbolic name which can be resolved via local databases or
name servers.
Problems with IP addressing are:
IP datagrams only specify a host as destination. But how does a
datagram reach the right application? TCP and UDP use 16-bit port
numbers for this purpose. Port numbers are more flexible as
process ids, as one process may have several distinct connections with
another process at the same time using several ports.
One port can also be used to receive
messages from several sources. Figure 21 illustrates the
port model. Only one direction of data flow is shown in Figure 21
to simplify the figure, therefore client ports are omitted.
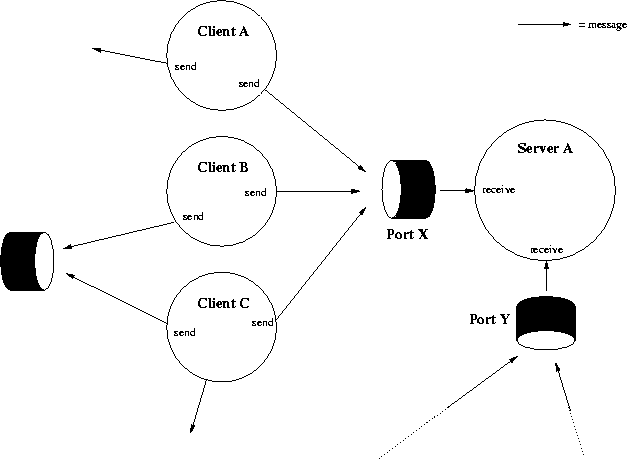
Servers normally listen for client requests on a
well-known port number. Well-known
port numbers are defined in the file /etc/services. The
World Wide Web HTTP (HyperText Transfer Protocol) as an example normally
uses TCP and UDP port number 80.
The Internet Assigned Numbers Authority (IANA) manages
the well-known port numbers between 1 and 1023. On UNIX systems
the well-known ports are reserved ports. Only processes with
superuser privileges can assign themselves a reserved port number. This
increases security for rlogin and other areas.
Client processes normally do not care what port number they use,
as long as the used port number is unique on their host.
Normally the operating system assigns an ephemeral (short lived)
port for them. This is due to the fact client processes are started and
terminated when the user decides, whereas server processes typically run as
long as the host is up.
Communication protocols use techniques of multiplexing and
demultiplexing throughout the layered hierarchy. When sending a message,
the different protocol layers of the source computer include extra bits
that encode the message type, protocol used, etc.
The destination computer uses this extra information to guide the
processing. Figure 22 illustrates the process of demultiplexing
an Ethernet frame up to the application level.
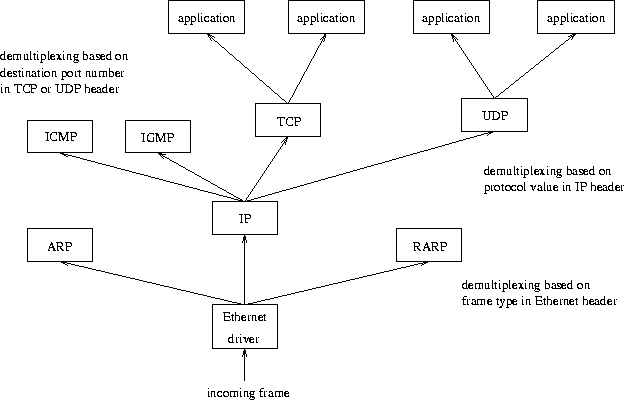
The Internet Protocol (IP) is used by all high-level protocols, like
TCP and UDP, in the Internet Protocol suite to transfer data.
IP provides an unreliable, connectionless, best effort datagram
delivery service.
Unreliable means that IP datagrams can get lost, duplicated,
or arrive in a different order than they were sent.
No connection has to be established before a datagram can be sent
to a destination.
The header of every IP datagram, shown in Figure 23, consists
of at least 20 bytes.
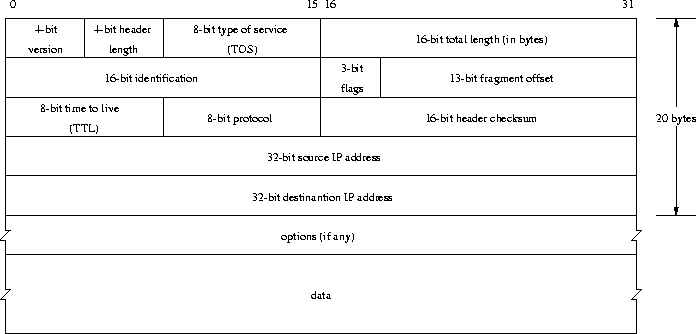
The current IP version is 4, version 6 is under development. Changes
between version 4 and 6 are summarized in Chapter 9.4.1.
The field header length gives the length of the IP header in 32-bit
words. The type of service field indicates whether this datagram requests
special handling or not. The field total length states the length of the
IP datagram including the header. Therefore the maximum data size of an IP
datagram is 65515 bytes. Most link layers can not handle such big packets.
IP automatically fragments datagrams if necessary. The identification
field uniquely identifies each datagram sent by a host. The flags
and fragment offset field are used for fragmentation of large datagrams.
The time to live field limits the number of routers through which
a datagram can pass. The protocol field specifies which type of
data the datagram carries (e.g. UDP or TCP), this is needed for demultiplexing
IP datagrams (see Chapter 5.6). The header checksum is a checksum
over the IP header.
Source IP address states the origin of an IP datagram,
destination IP address states where it should be sent to. Various options can
be specified.
The internet protocol is specified in [RFC 791].
The User Datagram Protocol (UDP), Figure 24, enhances IP datagrams
in such a way that
they become usable for processes: port numbers are included which allows
identification of the sending and the receiving process. The UDP optional checksum
covers the UDP header, some fields of the IP header, and the data.
The length field states the number of bytes in the UDP datagram including
the header.
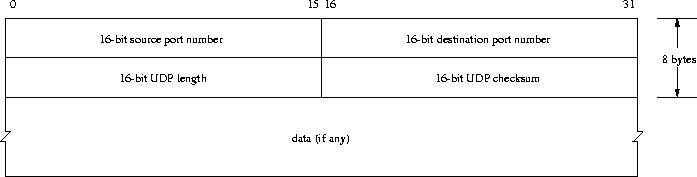
UDP is just an interface to make IP datagrams usable from different processes. Therefore UDP is as unreliable as IP, there is no guarantee that UDP datagrams reach their destination. UDP is specified in [RFC 768].
The Transmission Control Protocol, or short TCP, provides a connection-oriented, full-duplex, reliable, byte stream service. TCP uses IP as data exchange protocol. Before two applications can transfer data via TCP, a connection has to be established. With TCP message boundaries not being visible to the application, applications use TCP data streams like normal UNIX I/O streams. TCP provides reliability by doing the following:
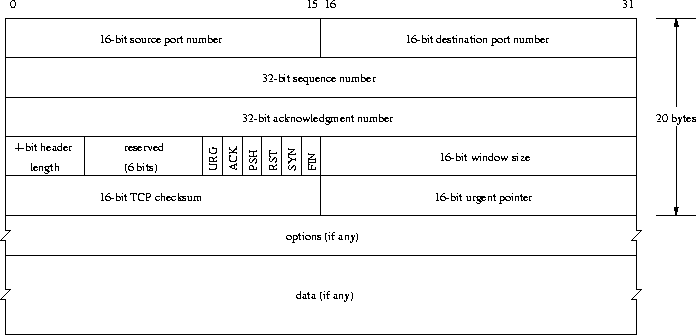
The TCP header, shown in Figure 25, consists of at least 20 bytes.
Like UDP datagrams, TCP segments contain source and destination port numbers
to identify the sending and receiving process. Together with the source and
destination IP address they uniquely specify each connection.
The sequence number is used to identify the position of the data in
the segment. The acknowledgment number contains the next sequence number
that the sender of the acknowledgment expects to receive.
The header length field gives the length of the header in 32-bit words.
Various flags are used for connection establishment and control status
information. The window size field is used to announce the number of
bytes the sender of the segment is willing to accept. The checksum
covers the TCP header, some parts of the IP header, and the TCP data.
The urgent pointer together with one flag can be used to advertise
data that should be delivered to the receiving process
as fast as possible. Some options may be used.
TCP is specified in [RFC 793].
Two aspects of how TCP ensures reliability are examined more closely: the TCP checksum and timeout algorithm.
For the purpose of data communication, the goal of a checksum
algorithm is to balance the effectiveness at detecting errors with the
cost of computing the check values [Part95].
IP, TCP, and UDP use a checksum that detects corrupted messages.
The checksum covers the header, and with TCP and UDP also the transferred data.
The so-called TCP checksum is a 16-bit ones complement
sum of the data. This sum will catch any 1 bit error in the data, and over
uniformly distributed values of data it is expected to detect other types of
errors at a rate proportional to 1 in 2 ![]() [RFC 1071].
[RFC 1071].
When the checksum is calculated for TCP and UDP a so-called pseudo
header (various parts from the IP header) is included in the calculation.
The TCP checksum can be computed very quickly. Tests have shown that it is
good enough for most purposes, although
the checksum has a major limitation: regardless of the order in which the
16-bit values appear, the sum stays the same.
Details about the TCP checksum can be found in [RFC 1071].
Because of the variability of the networks that compose an
internetwork system and the wide range of uses of TCP connections the
retransmission timeout must be dynamically determined [RFC 793].
There also is a large variability of delays in different routers.
Therefore an adaptive retransmission algorithm is used.
TCP monitors the performance of every connection, and tries to deduce reasonable values for timeouts. TCP records the time for every outgoing segment and the time when an acknowledgment for that segment arrives. From these two time stamps the round trip time RTT (the difference between the two times) is calculated. This value is then used to slowly adjust an estimated smoothed round trip time, SRTT, a weighted average:
![]()
If the chosen ![]() is close to 1, the weighted average is nearly
immune to changes that last a short time like a single segment that
encounters long delay. If the value for
is close to 1, the weighted average is nearly
immune to changes that last a short time like a single segment that
encounters long delay. If the value for ![]() is chosen close to 0,
the weighted average responds quickly to delay changes.
is chosen close to 0,
the weighted average responds quickly to delay changes.
The retransmission timeout RTO is then calculated as a function of the current round trip estimate. In [RFC 793] the function
![]()
is suggested where UBOUND is an upper bound on the timeout (e.g., 1 minute),
LBOUND a lower bound on the timeout (e.g., 1 second),
and ![]() a delay variance factor (e.g., 1.3 to 2.0).
Practice has shown that this function does not always have the desired
result. Therefore more complicated algorithms and functions were developed that
behave better in most situations. These algorithms are, unfortunately,
too long to be covered in this document. The interested reader
might refer to [Com95, page 209-216].
a delay variance factor (e.g., 1.3 to 2.0).
Practice has shown that this function does not always have the desired
result. Therefore more complicated algorithms and functions were developed that
behave better in most situations. These algorithms are, unfortunately,
too long to be covered in this document. The interested reader
might refer to [Com95, page 209-216].
The TCP/IP protocol suite includes protocols for file transfer, remote login facilities and other purposes.
The File Transfer Protocol (FTP) is a standard protocol which allows computers connected by TCP/IP to exchange data. FTP offers some facilities beyond the transfer function itself:
Details about the FTP protocol can be found in [Com95, Chapter 24].
The TELNET protocol provides a simple remote terminal protocol. It allows a user to sit on one computer and work remotely on another computer. Details about the TELNET protocol can be found in [Com95, page 408ff].
rlogin is a UNIX remote login service (derived from BSD UNIX). It is more powerful than telnet, but is limited to UNIX. rlogin exports part of the users environment to the remote machine, including information like the terminal the user is using. Remote login sessions appear to a user almost exactly as a normal local login session.
There are some basic network utilities offering low-level network management within UNIX. The most common ones are described in Table 13.
| Program | Purpose |
| dnsdomainname | show the system's domain name |
| hostname | show or set the system's host name |
| netstat | display active network connections |
| nslookup | query Internet name servers interactively |
| ping | checks connection to destination address by sending ICMP ECHO_REQUEST packets |
| rdist | remote file distribution client program |
| traceroute | print the route packets take to network host |
This chapter has examined the protocol normally used for
UNIX interprocessor communication. The next chapter can now describe
how the TCP/IP protocol suite can be used within programs to exchange data.
The TCP/IP protocol suite is one of the most used protocol suites. IP is the basic protocol for data exchange. For applications UDP and TCP are of interest. UDP provides an unreliable, connectionless datagram service, while TCP provides a reliable, full-duplex, connection-oriented byte stream service. Table 14 summarizes some important issues of IP, UDP, and TCP.
| Issue | IP | UDP | TCP |
| connection-oriented | no | no | yes |
| message boundaries | yes | yes | no |
| port numbers | no | yes | yes |
| data checksum | no | opt. | yes |
| positive ack. | no | no | yes |
| timeout and retransmit | no | no | yes |
| duplicate detection | no | no | yes |
| sequencing | no | no | yes |
| flow control | no | no | yes |